

Zhikai Zhang et al. / arXiv, 2026
Инженеры из Китая научили человекоподобного робота Unitree G1 играть в большой теннис, используя лишь фрагменты записей движений теннисистов-любителей вместо полноценных матчей. Робот освоил удары справа и слева, боковые перемещения и перекрестный шаг, а затем научился комбинировать их для отбивания мячей, летящих со скоростью выше 15 метров в секунду. Препринт статьи доступен на сайте arXiv.org, у проекта есть страница на GitHub.

Человекоподобных роботов уже учат отдельным видам спорта. Например, недавно американские инженеры представили систему HITTER, под управлением которой андроид Unitree G1 может играть в пинг-понг на уровне любителя. Большой теннис, очевидно, намного более сложная игра. Для обучения этому виду спорта в идеале нужны полные записи движений теннисистов, и собрать такие данные в условиях реального матча на полноразмерном корте технически крайне сложно: корт имеет большую площадь, а тонкие и быстрые движения запястья руки во время ударов плохо поддаются видеофиксации.
Разработчики под руководством И Ли (Li Yi) из Университета Цинхуа совместно с коллегами из Пекинского университета, Шанхайской лаборатории и компании Galbot придумали, как обойти это ограничение. Вместо записей полных матчей они использовали несовершенные данные — короткие записи фрагментов отдельных навыков, полученные с помощью оптической системы захвата движений. Несмотря на несовершенство исходных данных разработанная ими система управления, получившая название LATENT (от Learn Athletic humanoid TEnnis skills from imperfect human motioN daTa), позволяет человекоподобным роботам успешно обучаться навыкам игры в большой теннис.
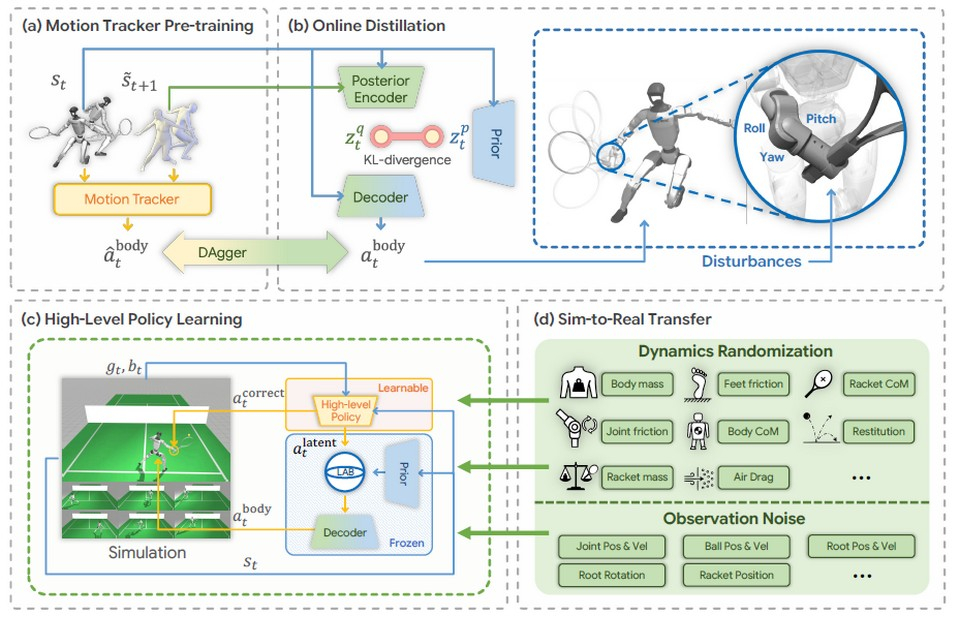
(a) Предварительное обучение нейросети-трекера движений на основе собранных несовершенных данных о движениях человека, (b) создание корректируемого скрытого (латентного) пространства действий с помощью метода дистилляции, (c) обучение высокоуровневой политики корректировать и комбинировать скрытые действия для решения теннисных задач, (d) перенос стратегии в реальный мир путем рандомизации динамики и зашумления данных наблюдений
Zhikai Zhang et al. / arXiv, 2026
Для сбора данных пять теннисистов-любителей выполняли отдельные элементы — удар справа, слева, боковой и перекрестный шаги. Их движения фиксировались оптической системой захвата движений. Зона захвата составляла всего 3 × 5 метров — более чем в 17 раз меньше площади теннисного корта. Общий объем записей составил пять часов. Эти данные были оставлены в сыром виде: разработчики намеренно не проводили никакой ручной очистки, редактирования или специальной разметки видеоряда. Собранные данные затем пересчитали в координаты суставов андроида Unitree G1.
Обучение политики управления проходило в три этапа. Сначала нейросеть-трекер училась воспроизводить фрагменты движений в симуляторе MuJoCo, причем управление запястьем правой руки с ракеткой намеренно исключали, а вместо этого подавали случайные возмущения. Затем через дистилляцию из трекера извлекали компактное латентное пространство навыков. Для каждого состояния робота система дополнительно обучала модель типичных действий, так как, например, при боковом перемещении ожидаемые движения суставов заметно отличаются от тех, что нужны при замахе ракеткой. На третьем этапе высокоуровневую политику обучали методом PPO комбинировать навыки и одновременно выдавать сигналы коррекции запястья для нанесения точного удара.
Ключевым шагом стал так называемый «барьер латентных действий» — механизм, ограничивающий область поиска политики окрестностью типичных действий для каждого состояния с учетом того, насколько сильно суставы робота могут отклоняться от нормы. Без него политика управления могла генерировать слишком дерганые нереалистичные движения. В симуляции на 10 тысяч испытаний LATENT показала долю успешных возвратов мячей свыше 96 процентов при ударах справа и около 82 процентов при ударах слева, что существенно выше, чем у альтернативных методов, использованных авторами для сравнения: лучший из них при ударах справа достиг лишь 72 процентов успеха. Показатели плавности движений у LATENT также оказались лучшими.
Для переноса на реального робота инженеры применили рандомизацию динамики мяча и шум в наблюдениях, включая задержки и выпадения кадров. На корте робот Unitree G1 под управлением LATENT с закрепленной на руке теннисной ракеткой смог не просто отбивать одиночные мячи, но и стабильно поддерживал розыгрыши с игроками-людьми, многократно обмениваясь мячом. Робот показал около 91 процента успешных возвратов мячей справа и около 78 процентов — слева. Без рандомизации показатель падал до 17–25 процентов. Кроме того, в симуляции два экземпляра политики смогли провести матч друг с другом, отбив последовательно до 25 ударов подряд. В будущем авторы планируют заменить внешнюю систему захвата движений на встроенное зрение робота, а также перейти к формату полноценного матча, использовав мультиагентное обучение.
Четвероногих роботов тоже пытаются научить играть в спортивные игры. Недавно команда инженеров из Швейцарии обучила робособаку с манипулятором на спине играть в бадминтон.